A scraping pipeline and Telegram bot that gives event organizers live ticket-sales numbers from BookMyShow, which has no public API.
Why it exists
I built this for SmallWorld, one of the bigger event-hosting companies in India. Their whole business runs on selling out shows, and the one number that tells them whether that's happening lived somewhere they couldn't get at it.
When you list an event on BookMyShow, India's largest ticketing platform, you can watch it sell on their dashboard and nowhere else. No public API, no export, no feed. So an organizer running ten shows across cities has no single place to answer a basic question: how is each one actually selling right now? They were checking dashboards by hand, one show at a time. That stops working the moment you have more than a couple of events.
The fix had two halves. Get the data out of BookMyShow reliably, then put it somewhere the organizers already spend their day. That turned into a scraper and a Telegram bot, kept as two separate apps on purpose.
Getting the data out
The scraper is a TypeScript and Node.js background service that pulls live seat-availability data off BookMyShow and lands it in a Supabase Postgres database.
The hard part isn't reading the page. It's not getting blocked. BookMyShow runs real bot detection, so a plain headless browser gets shut out fast. I used Patchright, a stealth fork of Playwright, with ghost-cursor on top so the mouse moves in human-looking arcs instead of teleporting around the page. Everything goes out through a pool of rotating residential proxies, so the traffic doesn't read as one machine hammering the site from a single address.
Speed matters too, because stale numbers are useless and there's a lot to keep current: more than 10,000 events. The service runs four headless browsers in parallel on a virtual display using Xvfb, staggered so they don't all hit the site at once and trip rate limits. The first version wrote each event back one row at a time, which fell apart at that volume. I switched to bulk SQL upserts that push a whole batch of events in a single statement instead of a query per show. That one change is most of why a full pass now finishes in a reasonable window. Prisma still handles the session database, where the lighter, structured reads and writes are a better fit for an ORM than the bulk event writes are.
On top of that sits a node-cron job that re-scrapes on an interval, plus a small authenticated HTTP API. POST /scrape kicks off an on-demand run when someone wants numbers right now, and GET /status is there for health checks.
The whole thing is Dockerized and deploys itself. Push to GitHub, GitHub Actions builds the image and pushes it to GHCR, and CapRover pulls and runs it on a DigitalOcean droplet. Keeping Chromium stable in production took some tuning of the shared-memory config, which is the kind of thing you only find out about once four browsers start crashing under load.
Putting it where they already are
The second app is a Telegram bot. It reads from the same Supabase Postgres database and lets an organizer ask about their events in plain chat: total ticket sales, the breakdown by venue, the numbers show by show. No dashboard to log into, no new tool to learn. They were already on Telegram all day, so the answers come to them there.
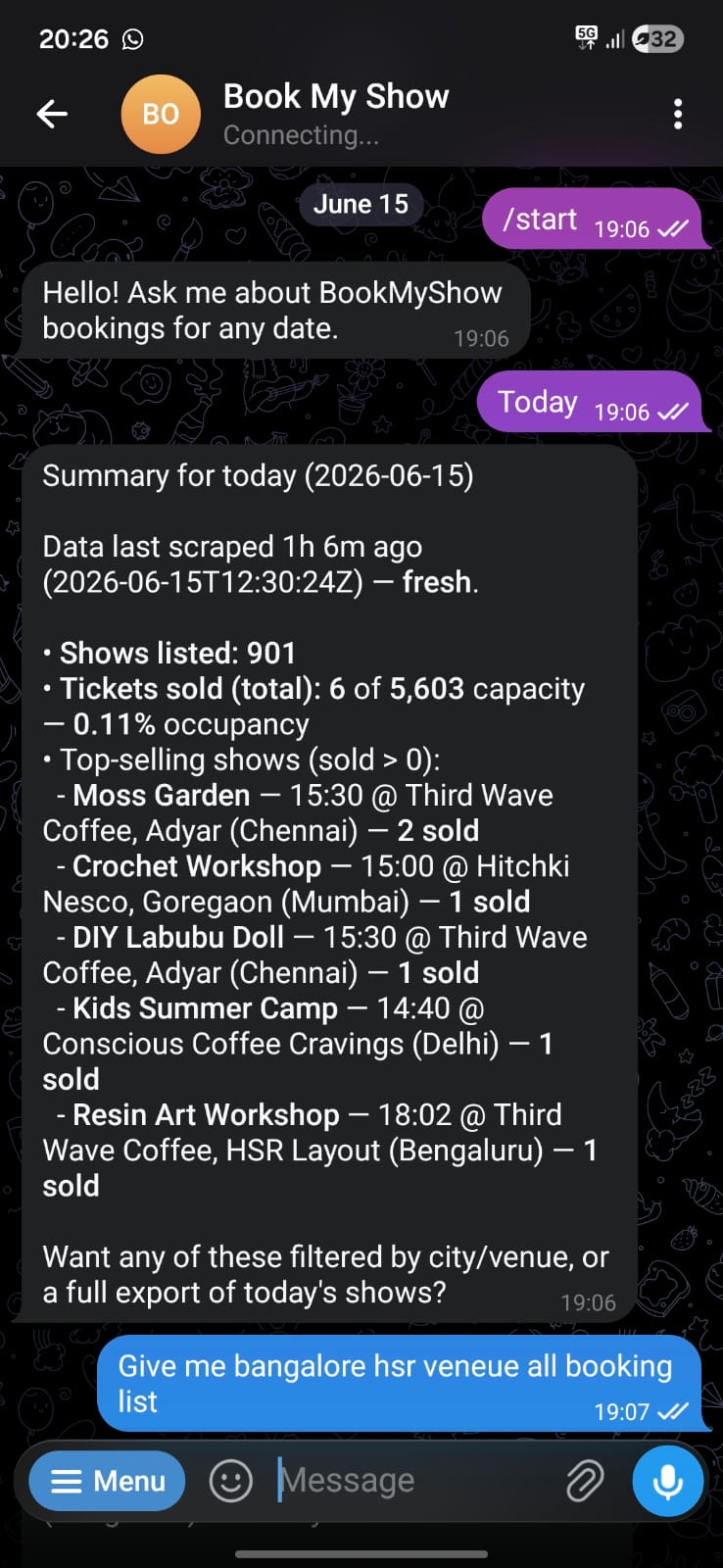
Ask it for "today" and it comes back with the shows listed, total tickets sold against capacity, occupancy, and the top-selling shows broken out by venue and city. From there an organizer can drill into a single venue or pull the full list, all without leaving the chat.
Why two apps instead of one
The scraper and the bot share one Supabase Postgres instance but run as completely separate services. That was deliberate. Data collection and the user-facing product fail for different reasons and change at different speeds. If the bot is down, the scraper keeps filling the database. If the scraping logic needs a rewrite because BookMyShow changed their page, the bot doesn't care, it's still reading the same tables. Drawing that line early kept both sides simple, and it meant I could keep tearing into the fragile scraping part without ever putting the thing organizers actually touch at risk.